Editor’s note: there is a massive set of data behind the Smart Chicago Chicago Works for You (CWFY) product– a citywide dashboard with three million requests, across fourteen services, all drawn from Chicago’s Open311 system. I asked Q. Ethan McCallum, a Chicago-based consultant focused on helping businesses to succeed and improve through practical use of data analysis, to review the data and see what we could learn. Here’s his take. –DXO
Drafting a game plan
Our first order of business was a brainstorming session, in order to establish a plan of action and narrow the scope of our efforts.
CWFY data includes temporal and spatial elements, in addition to the service request counts. That makes for a very rich dataset and an open-ended analysis effort. At the same time, we wanted to this to be a reasonably simple, lighthearted exercise and we were under time constraints.
After some brainstorming, we chose to limit our exploration to the daily counts of service requests, and we would search for interesting and non-obvious connections. Specifically, we wanted to look for unexpected correlations in the data: would two services experience similar movement in request volume? and if so, would we be surprised by the connection?
Statistically speaking, correlation is expressed as a numeric measure called the Pearson correlation coefficient. Often written as as r, it can take on values from -1 through 1. A value of 1 means the two series of numbers — in our case, daily counts of service requests — move in perfect unison. (Movement in one series doesn’t necessarily cause movement in the other, mind you; it just means that they walk in lock-step.) A score of -1 means that the two series move in opposite ways: if one value increases, the other decreases. When R is 0, the two series’ movements have no clear relation.
Interpretation of r is somewhat subjective: we can say that values “close to” 1 or -1 indicate a strong relationship and values “near” 0 do not indicate a relationship; but there is no clear-cut definition of “close” in this case. People often say that r greater than 0.7 or less than -0.7 indicates reasonable positive or negative correlation, respectively. Then again, you may want something closer to 0.9 or -0.9 if you’re trying to make a strong case or working on sensitive matters.
In search of the non-obvious
Once we had established our game plan, we fired up some R and Python and got to work. (Note that this is a rarity in the world of data analysis. Data prep and cleanup often account for most of the work in an analysis effort. Because of how we’d built CWFY, the data was already clean and in the format we needed.)
We found a number of reasonably-strong correlations among the request types — with r values ranging from 0.60 to 0.76 — but we were disappointed that none struck us as particularly out of line or surprising. For example:
- There are three request types related to broken street lights (
street_light_1_out, alley_light_out, street_lights_all_out, if you’re looking at the raw data) and they exhibit similar shape in call volume. One plausible explanation is that several people call to report the same issue, which gets filed under different categories.
- Building and sanitation violations move in similar fashion. In this case, callers may express different concerns about the same issue, so 311 puts those in different buckets.
- Rodent complaints sometimes pair up with broken street lights. Perhaps the rats felt more free to move about under cover of darkness?
These are just hypotheses, therefore deserving of additional research. That said, we were looking for correlations that did not make immediate sense. None of these fit the bill, so we decided to look elsewhere.
Blame it on the rain?
When you don’t find anything of interest in one dataset, you can sometimes mash it up with another. Our data had a temporal element — number of service requests over time — so it made sense to pair it up with other time-based data related to Chicago. That led us to everyone’s favorite small-talk topic, the weather.
Our goal was to see whether 311 service request volume would match up with temperature patterns or rain storms. In particular, we asked ourselves:
- If the temperature rises above 90 degrees, do people report more cases of abandoned vehicles?
- Do 311 calls for tree debris coincide with rain storms?
Acquiring weather data is surprisingly painless. The National Climatic Data Center provides an API for storm events, and downloads for daily temperature reports.
While this data was very clean and easy to work with, it did not provide strong support for our new hypotheses: in both cases, r fell between 0 and 0.08. While many people will debate what is “reasonably close” to 0, we decided that 0.08 was close enough for us. (We readily admit that the first question was a lark, but the second one seemed quite reasonable.)
What next?
We took a very quick, cursory glance at the CWFY data to poke at a couple of fun questions. This was hardly a thorough data analysis on which we would base decisions, but instead a whimsical trip across a new dataset. Our data excursion left us empty-handed, but it was fun nonetheless.
In most data analysis exercises, this is when we would have returned to the proverbial drawing board to formulate new questions, but we had reached our time limit.
Now, it’s your turn: you probably have your own ideas, and the opportunity to perform more in-depth research. We make the CWFY data available via our API, which means you are free to build on it and explore it to at your leisure. Where will your experiments take you?
If you’re eager to work the data, but aren’t sure where to begin, we’ve included a short list of starter ideas below.
Have you found an interesting perspective on the CWFY data? Please let us know. We encourage people who anaylze or build apps on the data to contact us at [email protected]. We look forward to hearing from you.
The Chicago Works for You Data: starter ideas for analysis projects
Short on ideas? Please try these:
- deduplication: try to identify when the same issue was reported under different names (e.g., the various street light incidents)
- take a deeper look at the correlations we found: hypothesize as to why those correlations may exist, then find evidence to test that hypothesis
- geospatial analysis: break down the requests by ward, and see whether the correlations remain. (For example: what if it was sheer coincidence that rat complaints moved in tandem with graffiti removal? What if those calls were on opposite sides of town?) Also, see what new correlations arise.
- time series analysis: shift the data forward and backward in search of lagged correlations (for example, “a rise in calls for Request Type X often predate a similar rise in calls for Request Type Y”)
- blend with other data sets: for example, pair up the CWFY data with something from the Chicago Data Portal.
New to data analysis? You may find the following books helpful:
- R in Action (Kabacoff) – how to use the R statistical toolkit to explore data
- Bad Data Handbook (McCallum) – a series of contributed tales on working through data problems
- Python for Data Analysis (McKinney) – use the popular Python programming language to analyze your data


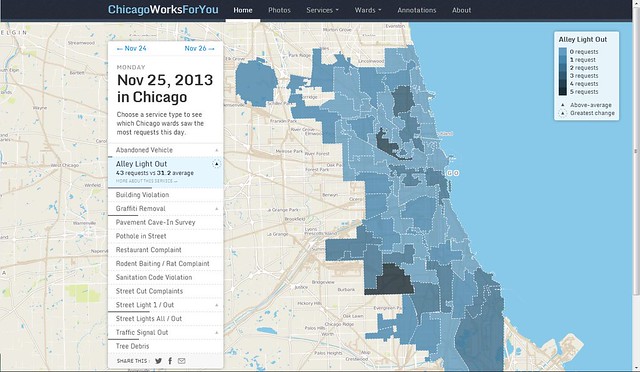
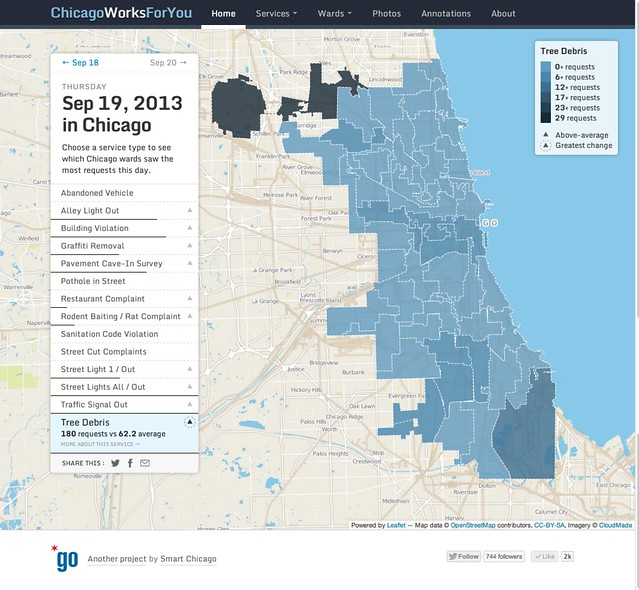 This site is going to be a central tool for Smart Chicago as we continue our work around internet access, digital skills, and civic apps. It allows us to engage residents, government, and developers around shared data so that we can all work together to make Chicago work better for all.
This site is going to be a central tool for Smart Chicago as we continue our work around internet access, digital skills, and civic apps. It allows us to engage residents, government, and developers around shared data so that we can all work together to make Chicago work better for all.